前言
每种语言都需要编译才能运行,编译的过程就是把源代码变成指令的过程,这个指令便是机器听得懂的二进制可执行文件。
C语言的编译分为以下几个步骤:预处理 -> 编译 -> 汇编 -> 链接 -> 执行
预处理
命令:gcc -E x.c
- 移除注释:
- 文件包含: 预处理器处理
#include指令,将指定的头文件内容插入到源文件中 - 宏替换: 处理以
#define定义的宏,将宏名称替换为其对应的值。创建常量或简化代码 - 条件编译: 预处理器处理条件编译指令,如
#if、#ifdef、#ifndef等,根据条件编译代码的不同部分。这使得可以根据不同的编译条件包含或排除代码块。 - 字符串化:把分行的变成一起
- 标识符连接
编译
编译的过程包涵:词法分析 -> 语法分析 -> 语义分析 -> 中间代码生成 -> 优化 -> 目标代码生成
词法分析
识别并记录源文件中的每一个token
- 标识符, 关键字, 常数, 字符串, 运算符, 大括号, 分号…
- 还记录了token的位置(文件名:行号:列号)
C代码其实就是字符串
所以说,词法分析器本质上是一个字符串匹配程序
clang -fsyntax-only -Xclang -dump-tokens a.c语法分析
按照C语言的语法将识别出来的token组织成树状结构(AST)
- AST(Abstract Syntax Tree), 可以反映出源程序的层次结构
- 报告语法错误, 例如漏了分号
clang -fsyntax-only -Xclang -ast-dump a.c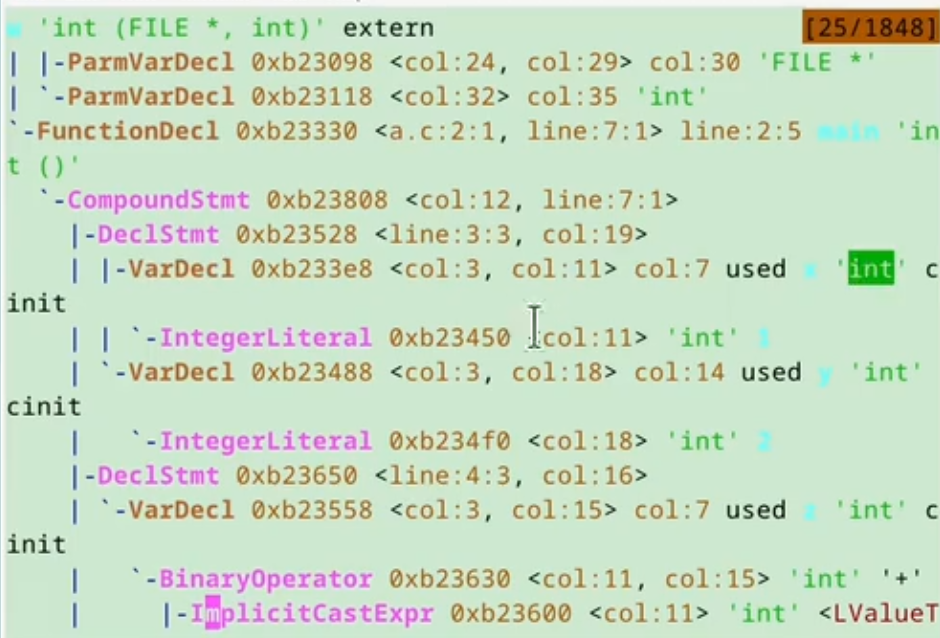
语义分析
按照C语言的语义确定AST中每个表达式的类型
- 相容的类型将根据C语言标准规范进行类型转换
- 算术类型转换
- 报告语义错误
- 未定义的引用
- 运算符的操作数类型不匹配(如
struct + int) - 函数调用参数的类型和数量不匹配
- …
但大多数编译器并没有严格按阶段进行词法分析, 语法分析, 语义分析
静态程序分析
在不运行程序的情况下对其进行分析
- 本质就是分析AST中的信息
- 大部分编译器分析报错就是用的静态程序分析
可以检查/分析以下方面
- 语法错误, 代码风格和规范, 潜在的软件缺陷, 安全漏洞, 性能问题
clang use-after-free.c --analyze -Xanalyzer -analyzer-output=text中间代码(抽象层)生成
中间代码(也称中间表示, IR) = 编译器定义的, 面向编译场景的指令集
将C语言状态机翻译成IR状态机
- 变量 -> %1, %2, %3, %4, …
- 语句 -> alloca, store, load, add, call, ret, …
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 1, i32* %2, align 4
store i32 2, i32* %3, align 4
%5 = load i32, i32* %2, align 4
%6 = load i32, i32* %3, align 4
%7 = add nsw i32 %5, %6
store i32 %7, i32* %4, align 4
%8 = load i32, i32* %4, align 4
%9 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([8 x i8], [8 x i8]* @.str, i64 0, i64 0), i32 noundef %8)
ret i32 0
}clang -S -emit-llvm a.c为什么不直接翻译到处理器ISA?
- 基于抽象层进行优化很容易
- 可以支持多种源语言和目标语言(硬件指令集)
优化
如果两个状态机在某种意义上 “相同”, 就可以用 “简单”的替代 “复杂”的
- “简单” = 状态少(变量少), 激励事件少(语句少)…
- 最 “复杂” = 严格按照语句的语义来翻译(严格的状态转移)
“相同” = 程序的可观测行为(C99 5.1.2.3节第6点)的一致性
- 对volatile修饰变量的访问需要严格执行
- 程序结束时, 写入文件的数据需要与严格执行时一致
- 交互式设备的输入输出(stdio.h)需要与严格执行时一致
这给编译器优化提供了非常广阔的空间
- 也是因为太广阔, 以至于编译器里面有很多bug
- 理论上来说, “判断任意两个程序的可观测行为是否一致”是不可判定的
加个volatile后会使用严格的状态转移
#include <stdio.h>
int main() { // compute 1 + 2
int x = 1, y = 2;
volatile int z = x + y;//这样就不会直接算出来进行优化
printf("z = %d\n", z);
return 0;
}目标代码生成
将IR状态机翻译成处理器ISA状态机
- %1, %2, %3, %4, … -> {R, M}
- alloca, store, load, add, call, ret, … -> ISA的指令
- 同时进行目标ISA相关的优化
- 把经常使用的变量放到寄存器, 不太常用的变量放到内存
- 选择指令数量较少的指令序列
- 有很多优化的空间, 这里不深入讨论
clang -S a.c
clang -S a.c --target=riscv32-linux-gnu
gcc -S a.c # 也可以用gcc生成
# apt-get install g++-riscv64-linux-gnu
riscv64-linux-gnu-gcc -march=rv32g -mabi=ilp32 -S a.c
//可以通过time report观察clang尝试了哪些优化工作
clang -S a.c -ftime-report汇编
根据指令集手册, 把汇编代码(指令的符号化表示)翻译成二进制目标文件(指令的编码表示)
二进制文件不能用文本编辑器打开来阅读了
- 需要binutils(Binary Utilities)或者llvm的工具链
objdump -d a.o
riscv64-linux-gnu-objdump -d a.o
# alias rvobjdump="riscv64-linux-gnu-objdump"
llvm-objdump -d a.o # llvm的工具链可以自动识别目标文件的架构, 用起来更方便//生成
gcc -c a.c
riscv64-linux-gnu-gcc -march=rv32g -mabi=ilp32 -c a.c
# alias rv32gcc="riscv64-linux-gnu-gcc -march=rv32g -mabi=ilp32"链接
合并多个目标文件, 生成可执行文件
有很多crtxxx.o的系统文件
- crt = C runtime, C程序的运行时环境(的一部分)
- 可以通过
objdump确认
gcc a.c --verbose
gcc a.c --verbose 2>&1 | tail -n 2 | head -n 1 | tr ' ' '\n' | grep '\.o$'执行
把可执行文件加载到内存, 跳转到程序, 执行编译出的指令序列
./a.out
# 通过一些配置工作, RISC-V的可执行文件也可以在本地执行
# apt-get install qemu-user qemu-user-binfmt
# mkdir -p /etc/qemu-binfmt
# ln -s /usr/riscv64-linux-gnu/ /etc/qemu-binfmt/riscv64
file a.out
a.out: ELF 64-bit LSB pie executable, UCB RISC-V, version 1 (SYSV)...
./a.out # 实际上是在QEMU模拟器中执行